Agent problems surface immediately — not from user complaints.
Continuous scoring of production traffic. Drift alerts. Cost transparency. Automatic retraining when quality drops below your threshold.
For development teams.
- → Drift detection on every axis
context_adherence drops 0.78 → 0.61? Flagged instantly. Not after 500 bad responses reach users.
- → Auto-retrain triggers
Score drops below threshold → retraining loop starts automatically. Human approval optional.
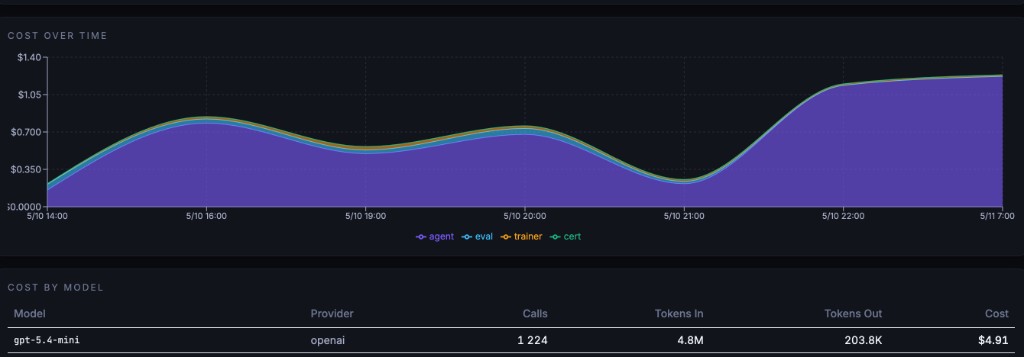
- → Cost tracking per surface
Agent calls, eval runs, trainer iterations, cert checks — every dollar allocated. Know where budget goes.
- → Live certification scoring
Same evaluators from training run on production traffic. No gap between what you tested and what runs.
Fleet-level visibility — agents don't degrade in isolation.
When one agent drifts, it often signals a shared dependency — a model update, a data source change, an API contract shift. Organizational-level monitoring catches systemic issues that per-agent dashboards miss.
Fleet health at a glance.
When scores drop, the cycle starts again — no manual intervention.
Monitoring and training share the same scoring infrastructure. When drift is detected, the system already has the eval chain, the task suite, and the baseline. Retraining is another iteration of the same loop.
For the business.
Real-time quality scores for every agent in production. Show clients and stakeholders that SLAs are met — with data, not promises.
from $4.91 per cycle (example run) — fully visible. Costs vary by model and config. No surprise bills. Budget with confidence.
Continuous certification proves compliance. Every alert, every score, every retraining decision — logged for auditors.
Know what your agents are doing in production.
Real-time scoring. Cost transparency. Automatic remediation.