Your agents work on real data. They should be tested on real data.
Graph-native environments that handle real complexity — databases, APIs, graph stores. Not toy sandboxes.
Evaluation environments match your production complexity.
Every environment is a typed graph. Vertices represent business entities — companies, shipments, ports, sanctions entries, beneficial owners. Edges represent relationships — owns, ships_to, flagged_by, routes_through. When an agent queries the environment, Node Resolution traverses this graph the same way production data would flow. A query like 'who owns the company that shipped this cargo?' resolves through the same entity chain your production system uses.
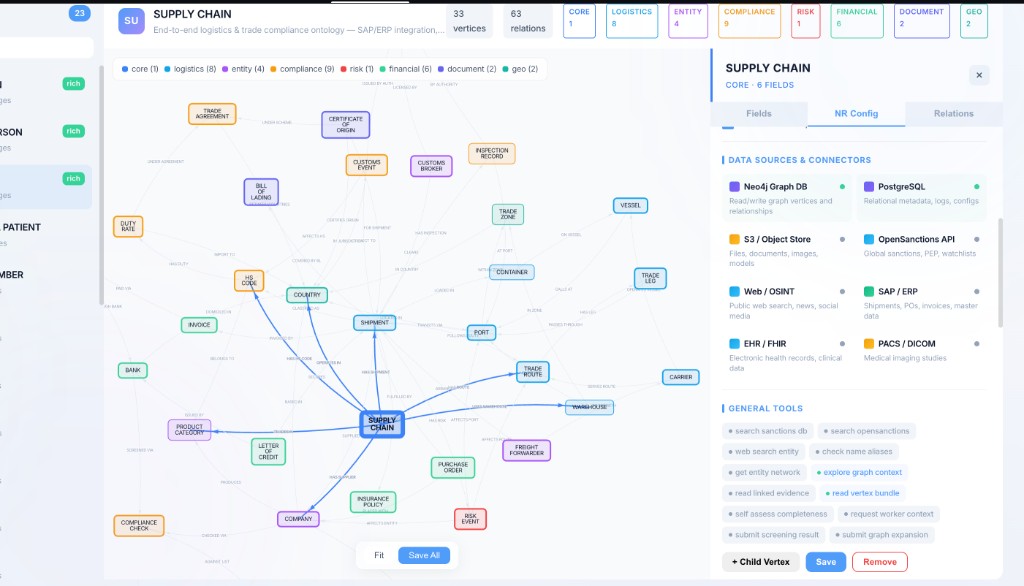
Agents are evaluated against your live data infrastructure.
Node Resolution integrates with your databases, APIs, and services. Evaluations run against live connections — not mocked responses.
Graph databases. Relationship traversal, pattern matching, multi-hop queries across business entities.
Relational data. Transactions, joins, aggregations — the backbone of most enterprise systems.
Enterprise resource planning. Purchase orders, invoices, materials, master data — real operational complexity.
External APIs. Third-party services, microservices, partner integrations — the edges of your system.
Every evaluation run is reproducible and auditable.
Deterministic resolution means identical inputs produce identical outputs. Every run can be replayed with identical environment state. Full audit trail of what came from baseline, what from override, what from default.
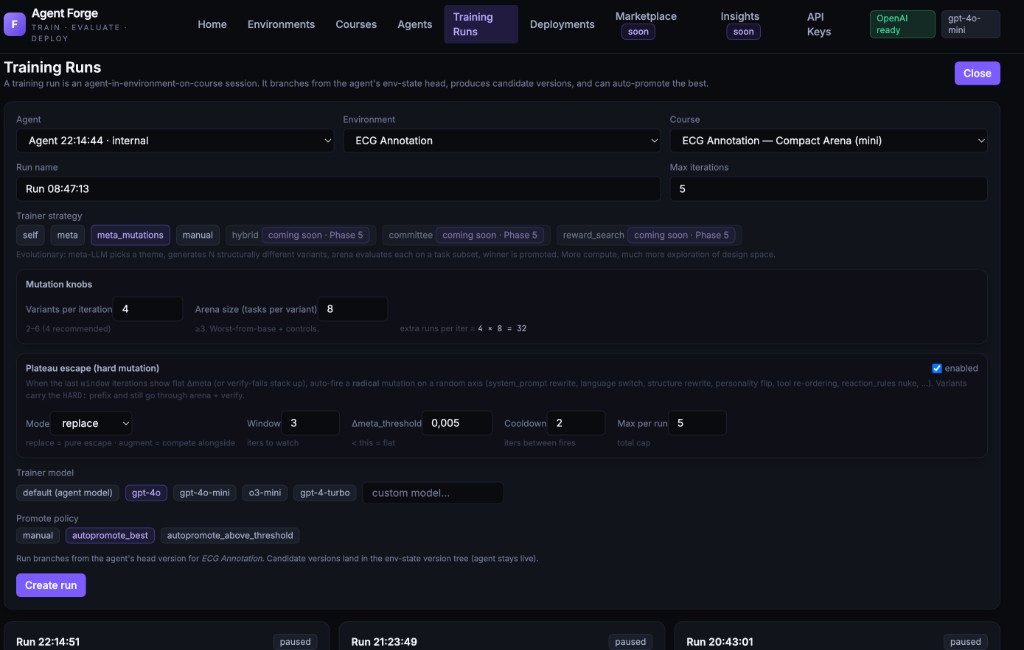
Agents trained on realistic environments perform in production.
Agents trained on simplified environments fail on production complexity. Node Resolution ensures evaluation environments match the real thing — graph depth, data volume, integration behavior.